August 20th, 2023
Image Optimisation Pipeline
Learn about serverless image optimization on AWS for a faster and smoother user experience.
Introduction
In today's world, latency and performance are critical for organisations, and optimising images becomes even more essential for an improved user experience and reduced data usage. A common technique is to resize images according to a user's device size to achieve this. For instance, if a user is viewing an image that is 2500px wide on a device that is 420px wide, the application would typically resize that image via CSS to fit that screen. Although visually acceptable, we have wasted a considerable amount of bandwidth and resources by sending a photo that large that wasn't even needed in the first place.
To address this problem, you can resize an image into multiple sizes that different devices can use, such as a sm size that will have 640px as its width, md will be 768px, and so on. This allows smaller devices only to request smaller images, saving on data usage and response times.
In this blog, we will create a seamless image optimisation pipeline by leveraging AWS Serverless offerings. The pipeline will receive an image and automatically create optimised versions in various sizes. We will set up its infrastructure using Terraform and deeply dive into the code for the Lambda function to process these images.
You can access the code for this blog post from this blog's github repository.
Overview of the architecture

Input Bucket
This bucket will be used to store the images for this application.
Lambda Function
The Lambda will receive an event from the S3 bucket, and with the info from that event, it will retrieve an object from the bucket and then optimise it by resizing it into various sizes; once done, it will upload the resized images to the output bucket.
For this blog post, we will write our Lambda with Nodejs/Typescript, and for image processing, we will use a popular library named sharp.
Lambda Layer
The sharp library's size can be quite large due to its dependencies and native code bindings. Rather than deploying it with Lambda, we will separate it using a lambda layer. This can significantly reduce the package size of Lambda, leading to numerous benefits, such as faster deployment times and reduced cold start times.
Output Bucket
Rather than uploading the optimised image back into the input again, we will store it in the output bucket. Otherwise, we might end up with a recursive scenario where the Lambda writes an image to the input bucket and then gets invoked again due to the same image upload, and the process keeps repeating itself. This pattern can be negligible to a certain extent on a standard ec2 machine, but Lambda's elastic and scalable nature can cost your company more than a few dollars.

Prerequisites
AWS account
AWS will be our choice of the cloud for this blog post; if you are not already registered, you can sign up for its free tier at AWS' sign up page.
Node
If you don't have Node.js installed, download the LTS(v18) version from the Node.js website.
Terraform CLI
If you don't have Terraform CLI installed, download it from Terraform's download page. For my Mac machine, I used homebrew to install it.
Project Structure
This application will be structured as follows:
- infrastructure: Contains all the Terraform code for this project
- packages: A collection of packages such as the Lambda itself and the Lambda layer.
- packages/image-optimiser: Code for the Lambda that will perform image optimisation
- packages/lambda-layers: Contains a collection of lambda layers. However, there will be just one lambda layer for our use case.
Enough talk; let's move on to building!
Provisioning the infrastructure
We will use Terraform to declare all the resources required to deploy this application to AWS.
In the root of your project, create a new directory named infrastructure
Within that directory, run the following command to initialise Terraform
terraform init
Next, we will create a new file named main.tf within the infrastructure directory.
You can replace ap-southeast-2, with your desired region.
It is a good practice to specify the required terraform and provider's version that our application requires.
terraform {
required_version = "~> 1.4.0"
required_providers {
aws = "~> 5.12.0"
}
}
Next, let's define the AWS provider block and the desired region in which we want to deploy our resources.
provider "aws" {
region = "ap-southeast-2"
}
Next, let's create the input bucket that we will upload the image to:
resource "aws_s3_bucket" "input_bucket" {
bucket = "image-optimization-input-bucket"
}
I have only specified the bucket's name as the argument and let other properties to their default values. Also, note that for security reasons, AWS, by default, blocks all the public access to the bucket, which is fine for our use case.
With a similar configuration, let's create the output bucket which the Lambda will upload optimised images to:
resource "aws_s3_bucket" "output_bucket" {
bucket = "image-optimization-output-bucket"
}
Now that we have created both the S3 buckets, we can declare the resources for the Lambda.
Before the Lambda, let's create the lambda layer it will use. Serverless.tf is an excellent package for this scenario; it makes it easy to provision layers and lambdas via Terraform, similar to the serverless framework.
module "sharp_lambda_layer" {
source = "terraform-aws-modules/lambda/aws"
create_layer = true
layer_name = "sharp-lambda-layer"
compatible_runtimes = ["nodejs16.x", "nodejs18.x"]
source_path = [
{
path = "${path.module}/../packages/lambda-layers/sharp/nodejs",
commands = [
"SHARP_IGNORE_GLOBAL_LIBVIPS=1 npm ci --arch=x64 --platform=linux --libc=glibc sharp",
"cd ..",
":zip"
]
}
]
}
In the above code, we have created a module via the terraform-aws-modules/lambda/aws module. To create the layer, you need to specify create_layer to be true. Although it is optional but for clarity, we have mentioned the runtimes that the lambda layer is compatible with.
It also needs a source_path to create the layer from, this can be just the path for the already zipped code, but to automate the packaging of the Lambda, we will define the commands that it needs to run on deployment.
To define the source path, we need to set the path where it will execute the commands via the path property. Then, we have defined an array of commands in the commands property. The first is the command to install sharp in the nodejs directory and then move one level directory up to zip the contents of that very nodejs folder via a special command :zip provided by the Serverless.tf module.
Moving on to the Lambda.
module "image_optimizer_lambda" {
source = "terraform-aws-modules/lambda/aws"
function_name = "image-optimizer-lambda"
handler = "index.handler"
runtime = "nodejs18.x"
memory_size = 2000
timeout = 30
environment_variables = {
OUTPUT_S3_BUCKET_NAME = aws_s3_bucket.output_bucket.id
}
source_path = [
{
path = "${path.module}/../packages/image-optimizer"
commands = [
"npm ci",
"npm run build",
"cd .esbuild",
":zip"
]
}
]
layers = [module.sharp_lambda_layer.lambda_layer_arn]
attach_policy_statements = true
policy_statements = {
input_bucket = {
effect = "Allow"
actions = ["s3:GetObject"]
resources = [aws_s3_bucket.input_bucket.arn, "${aws_s3_bucket.input_bucket.arn}/*"]
}
output_bucket = {
effect = "Allow"
actions = ["s3:PutObject"]
resources = [aws_s3_bucket.output_bucket.arn, "${aws_s3_bucket.output_bucket.arn}/*"]
}
}
}
Key takeaways from the above code apart from the standard configuration are:
- Memory size has been increased to 2000 MB from the default 128 MB. Although sharp is a highly-performing library, Lambda's computational power can still significantly affect its performance. To address this, we have increased Lambda's memory, if you're curious about how memory affects Lambda's performance, I would suggest reading AWS docs on Lambda's Memory and computation power.
- Timeout has been changed from the default of 3 seconds to 30 seconds, giving Lambda more time to process the image.
- We have specified the build process steps to avoid any reliance on external commands such as Make when packaging the Lambda. They are first installing the dependencies, build the Lambda for a production build and then again use the special command
:zipto package the contents of the built Lambda. - 2 IAM policies have been attached, the first being the permission for Lambda to retrieve the image from the input bucket and the second permission to upload the optimised image back to the output bucket. Also, note how we are not over-authorising our Lambda and adhering to the principles of only providing the least amount of privileges needed.
Now that both S3 buckets and Lambda have been created, we must set up an event notification on the input S3 bucket. Before we do that, lambda permission needs to be created, allowing that Lambda to be invoked by the input S3 bucket.
resource "aws_lambda_permission" "allow_bucket_invoke_lambda" {
statement_id = "AllowExecutionFromS3Bucket"
action = "lambda:InvokeFunction"
function_name = module.image_optimizer_lambda.lambda_function_name
principal = "s3.amazonaws.com"
source_arn = aws_s3_bucket.input_bucket.arn
}
Finally, create the event notification triggered on each upload to the input S3 bucket.
resource "aws_s3_bucket_notification" "input_bucket_notification" {
bucket = aws_s3_bucket.input_bucket.id
lambda_function {
lambda_function_arn = module.image_optimizer_lambda.lambda_function_arn
events = ["s3:ObjectCreated:*"]
}
depends_on = [aws_lambda_permission.allow_bucket_invoke_lambda]
}
Note the depends_on the argument, the Lambda permission needs to be created first before the notification can be set up.
With all the infrastructure required for this application being complete, let's write the code for Lambda!
Developing the Lambda
Create a new directory called packages containing the folders for Lambda and the layers.
Next, create another directory called image-optimizer.
Run the following command to initialise the project:
npm init -y
Next, let's install the required dependencies for this project
npm i @aws-sdk/client-s3 sharp
This installed two dependencies for our application, sharp and @aws-sdk/client-s3. I have already mentioned the role of sharp in this application, but let's touch on @aws-sdk/client-s3.
We will use it for retrieving and uploading images to S3. Also, why not use the classic aws-sdk library? Well, using @aws-sdk/client-s3 over aws-sdk can reduce your package by 75%! which can improve performance significantly. Also, the newer package offers first-class Typescript support compared to its older version. If you still need to be convinced, check out AWS's blog on why you should use the v3 SDK on nodejs18 runtime.
Next, let's install the dev dependencies for our Lambda:
npm i -D @types/aws-lambda @types/node esbuild typescript
Breaking down the dev dependencies:
- @types/aws-lambda: This provides the types for the s3 event the Lambda will receive.
- @types/node: Contains the type definitions for Node.js
- esbuild: esbuild is an extremely fast bundler that will bundle the code for this Lambda to reduce the package size.
- typescript: For type safety, we will use Typescript for this application.
Next, we must set up a tsconfig file to use Typescript in this project. When starting with a Typescript project, I usually use the tsconfigs provided by this repository as a base. We will choose the node18 tsconfig as a base for our project and make a few changes accordingly.
Let's create a new file called tsconfig.json with the following code:
{
"$schema": "https://json.schemastore.org/tsconfig",
"display": "Node 18",
"_version": "18.2.0",
"compilerOptions": {
"lib": ["es2022"],
"module": "ESNext",
"target": "es2022",
"outDir": "dist",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"moduleResolution": "node16",
"noEmit": true
}
}
One thing I would like to mention is noEmit, according to esbuild's documentation:
esbuild does not do any type checking so you will still need to run tsc -noEmit in parallel with esbuild to check types. This is not something esbuild does itself
This means that if we use only esbuild for type checking and compilation and a type error were to occur during build time, it would still pass and move on. This is why noEmit it needs to be true, as esbuild will handle the compilation, and we are telling tsc only to perform type checking and not emit any output.
Lambda Handler Code
With all the dependencies and configuration done, let's write the code for Lambda.
Create a new src directory in the lambda directory and a new imageOptimizer.ts file with the following contents:
import {
GetObjectCommand,
PutObjectCommand,
S3Client,
} from "@aws-sdk/client-s3";
import type { S3Event } from "aws-lambda";
import sharp from "sharp";
import type { Readable } from "stream";
import type { ImageDimensions, ImageSizeVariant } from "./types.js";
export class ImageOptimizer {
#s3Client: S3Client;
#imageDimensions: Map<ImageSizeVariant, ImageDimensions>;
constructor() {
this.#s3Client = new S3Client({ region: process.env.AWS_REGION });
this.#imageDimensions = new Map<ImageSizeVariant, ImageDimensions>([
["sm", { width: 640 }],
["md", { width: 768 }],
["lg", { width: 1024 }],
["xl", { width: 1280 }],
["2xl", { width: 1536 }],
]);
}
async #getObjectFromS3(
objectKey: string,
bucketName: string
): Promise<Buffer> {
console.log(`Getting object from S3: ${bucketName}/${objectKey}`);
const { Body } = await this.#s3Client.send(
new GetObjectCommand({
Bucket: bucketName,
Key: objectKey,
})
);
const stream = Body as Readable;
const dataChunks: Buffer[] = [];
return new Promise((resolve, reject) => {
stream.on("data", (chunk) => dataChunks.push(chunk));
stream.on("error", (err) => {
console.error(`Error fetching object from S3: ${err}`);
reject(err);
});
stream.on("end", () => resolve(Buffer.concat(dataChunks)));
});
}
async #resizeImage(
image: sharp.Sharp,
metadata: sharp.Metadata,
{ width }: ImageDimensions
): Promise<Buffer> {
console.log(`Resizing image to width: ${width}`);
if (!metadata.width || metadata.width > width) {
image.resize({
width,
fit: "contain",
});
}
switch (metadata.format) {
case "jpeg":
case "jpg":
image.toFormat(metadata.format, {
mozjpeg: true,
});
break;
case "png":
image.toFormat("png", { quality: 90 });
break;
default:
throw new Error("Unsupported image provided");
}
return await image.toBuffer();
}
public async handler(event: S3Event) {
const [record] = event.Records;
const bucketName = record.s3.bucket.name;
const key = decodeURIComponent(record.s3.object.key.replace(/\+/g, " "));
const originalBuffer = await this.#getObjectFromS3(key, bucketName);
const image = sharp(originalBuffer);
const metadata = await image.metadata();
for await (const [size, dimensions] of this.#imageDimensions) {
const [prefix, extension] = key.split(".");
if (!extension) {
throw new Error("No image extension provided");
}
const resizedImage = await this.#resizeImage(image, metadata, dimensions);
await this.#s3Client.send(
new PutObjectCommand({
Bucket: process.env.OUTPUT_S3_BUCKET_NAME,
Key: `${prefix}-${size}.${extension}`,
Body: resizedImage,
})
);
console.log(
`Resized image uploaded to S3: ${prefix}-${size}.${extension}`
);
}
}
}
That's a lot of code; let's break it down: We first set up a constructor for this class by creating an S3 client and a map of image dimensions for different screen sizes, such as sm, md, lg, xl and 2xl. Below is a list of the dimensions for each image size:
- sm: 640px width
- md: 720px width
- lg: 1024px width
- xl: 1280px width
- 2xl: 1530px width
Next, we write a utility getObjectFromS3 function, which, as the name suggests, retrieves an object from an S3 bucket with the given object key and bucket name. It then converts that result into a buffer, which the sharp library can consume.
Then we have the resizeImage function, why didn't we write this in the handler method itself? Because it is a good practice to separate business logic from the handler method, making the code more modular, testable, and portable. Circling back to the method, it takes a sharp image instance and the dimensions it needs to resize. It then maintains the original aspect ratio while adjusting the image based on its format. Also, depending on the format, it optimises it; for instance, JPEG/JPG it uses the mozjpeg library to do so, for png it reduces the quality to 90 on a scale of 1 to 100.
To orchestrate all of this, we have the handler method when an S3 event trigger happens:
- Extracts the bucket name and object key from the event.
- Uses
getObjectFromS3to fetch the original image - Prepare the image for resizing via the sharp library
- Loops through the predefined image dimensions and resizes the image for each size variant using resizeImage .
- Uploads each resized image to the output S3 bucket.
Next, create a new file called handler.ts, with the following code:
import type { S3Event } from "aws-lambda";
import { ImageOptimizer } from "./imageOptimizer.js";
const imageOptimizer = new ImageOptimizer();
export const handler = (event: S3Event) => imageOptimizer.handler(event);
This file will be the entry point for our application. By initialising the ImageOptimizer class outside the handler function, we leverage Lambda's execution context feature, which maintains it after an invocation for some time. This ensures that the class instance persists across invocations, preventing the need to recreate the S3 client with each call. To explore more about this, I suggest reading about the Lambda execution environment.
With the code now complete for the Lambda, let's write the build script that Terraform will run to bundle and transpile our Lambda during deployment.
Configuring Esbuild
When using esbuild for bundling, there are two options, you can either provide configuration, such as to which entry points it should bundle from, via CLI args such as esbuild --entryPoints foo.ts or you can write a script and call the build method provided by esbuild and write the configuration in a typesafe manner with type inference as well! For this application, we will choose the latter option.
Create a new file called esbuild.config.ts inside the image-optimizer folder and copy the following code.
import { build } from "esbuild";
build({
entryPoints: ["./src/handler.ts"],
bundle: true,
platform: "node",
target: "node18",
outfile: ".esbuild/index.js",
external: ["sharp"],
loader: {
".node": "file",
},
});
Breaking down the configuration:
- entryPoints: Specifies the file that will be evaluated first, which will load subsequent files and packages.
- bundle: Enables bundling meaning all the dependencies will be inlined. It is a recursive process meaning dependencies of the dependencies will also be inlined
- target: Sets the targeted environment to node18, which is the runtime our lambda will be running on.
- bundle: This is the folder from which our Lambda's code will be packaged and deployed.
- external: As we will use lambda layers for the sharp library, we will exclude it from our build. Rather than bundling it, the import for it will still be preserved, assuming it is already present rather than inline it.
Next, we must add a build script in package.json that Terraform can run to build the Lambda during deployment.
"build": "tsc && node esbuild.config.js"
To explore what the actual code we will be packaging to Lambda, you can run the following command and find it in the esbuild/index.js file.
npm run build
Lambda Layer
Create a new directory with the path packages/lambda-layers/sharp/nodejs from the root of your project.
Why do we create a nodejs folder rather than just using the sharp folder as the base for creating our layer? This allows lambda layers to support multiple languages, such as Python, Ruby etc., and each language would expect its dependencies in a specific folder. I have also included an excerpt from the AWS documentation on how Lambda determines the path which it needs to get the dependencies from:
When you add a layer to a function, Lambda loads the layer content into the /opt directory of that execution environment. For each Lambda runtime, the PATH variable already includes specific folder paths within the /opt directory. To ensure that your layer content gets picked up by the PATH variable, include the content in the following folder paths based on your runtime:
Moving on, let's next execute the following command to initialise the nodejs environment:
npm init -y
Next, run the following command to install the sharp library:
npm i sharp
Deployment
Congratulations if you've made it this far. Just a few more steps to see the final result.
Run the following command in the infrastructure directory to apply the terraform configuration:
terraform apply
If you're happy with the resources that Terraform will create, you can enter yes when it prompts you for confirmation.
Testing
Time to see the output, go to the AWS console and find the input S3 bucket we created and upload an image in that bucket.
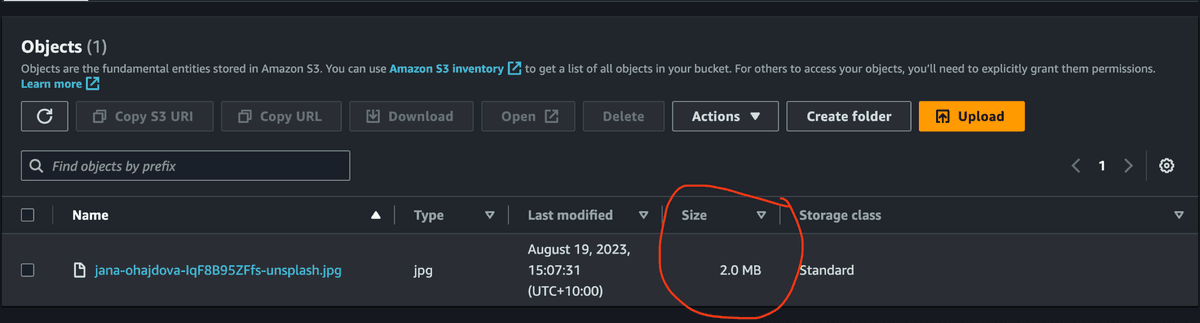
Please take note of the image size we uploaded, as it will be handy for comparing the optimised image in the output bucket. For this blog, I have picked the following image, which is 2 MB in size. Why did I pick it, though? Why not? German Shepherds are the best!

Next, let's check the output bucket to see if that image was optimised correctly:
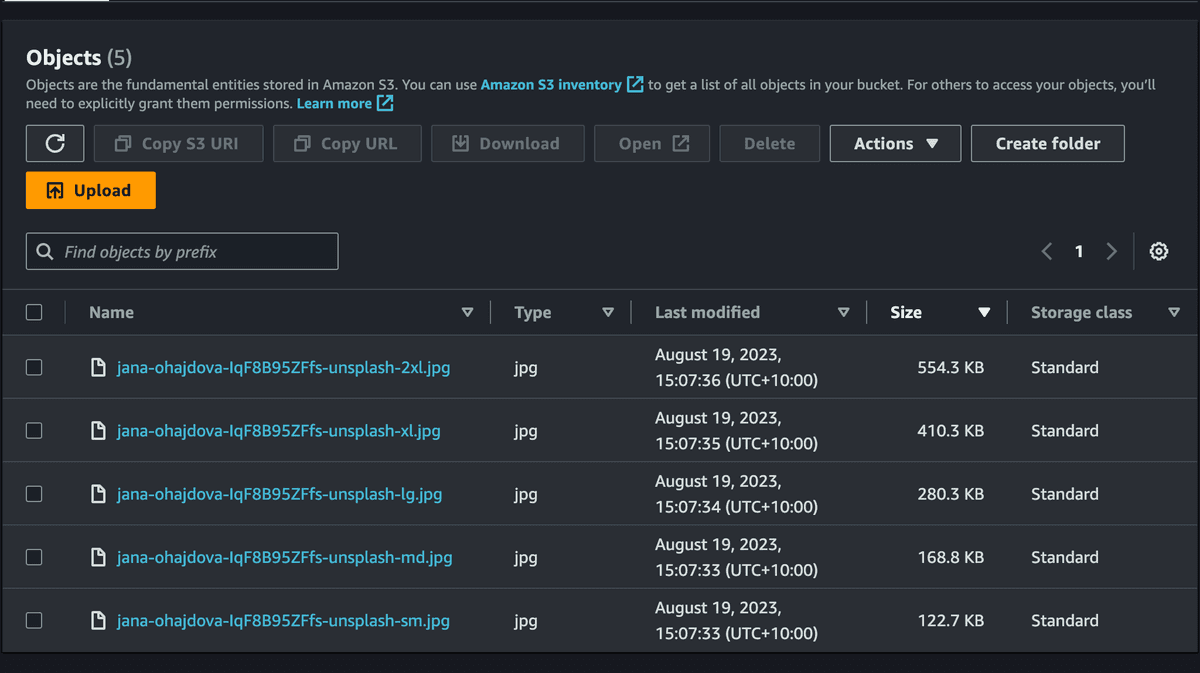
Hurray! Thanks to the sharp library, we generated different images for various sizes with each of their size as the suffix. Most importantly, notice the image sizes for each image; the 2xl image size was converted from 2MB to 554.3KB, which is over 70% savings in bandwidth. Let's look at the md and sm images that will likely be used on mobile devices; their sizes were 168.8KB and 122.7KB, respectively, which is over 90% savings on each image! Your user's data plan will thank you for such optimisation!
In addition, please note that the image used may or may not have been not optimised before, and please verify it by testing different kinds and sizes of images.
Also, make sure to verify the logs of the lambda function in Cloudwatch logs as well to ensure everything went as expected.
Conclusion
In this blog post, we successfully created an image optimisation pipeline using AWS Lambda, Typescript and Terraform. Testing displayed how we can improve the UX by saving bandwidth and data by resizing images.
Future Extensions
Although the implementation is complete, we can still make improvements. One such is that rather than resizing images on each S3 upload, it should poll them and do batch image processing. I will address this in my next blog post on how you can integrate AWS SQS to batch operations effectively. Stay tuned!
Thanks for reading this blog. Please feel free to reach out if you have any questions.